
[논문 리뷰] CoOp :: Learning to Prompt for Vision-Language Models
논문 Learning to Prompt for Vision-Language Models을 읽고, 최대한 다른 분들이 보셨을 때 이해가 잘 되도록 요약 및 핵심 내용 설명 위주로 Paper Review를 진행할 예정입니다.
보시고 피드백도 자유롭게 주셨으면 좋겠습니다!
🦾 Abstract
- 이전의 전통적인 방식들 : discrete한 label을 사용 (class를 label로 매핑)
- CLIP과 같은 대용량 pre-trained VL Model : Image와 Text를 공통 Feature Space에 정렬하고, prompting을 통해 downstream task에 대한 즉시 전이를 가능하게 함
그러나 이러한 모델들의 가장 큰 Challenge는 다음과 같다.
- Domain에 대한 전문 지식이 필요한 prompt engineering을 해야한다. 즉, task에 따라 또 다시 prompt engineering을 해야한다는 의미이다.
- 이에 따른 시간 소모가 크다.
- 미세한 단어 선택이 성능에 큰 영향을 준다.
그래서 제안한 것이 Context Optimization [CoOp]이다.
이는 CLIP과 같은 pre-trained VL model에 적용시켜서, image recognition과 같은 downstream task에 잘 적응하도록 한다.
CoOp을 아주 간단히 설명하자면, 학습 가능한 vector로 prompt의 context word를 구성하고, 이때 pre-trained parameter는 고정시킨다.
CoOp’s Contribution 요약
- 손으로 만든 prompts (hand-crafted prompts) 를 one/two shots으로 이길 수 있다.
- few shots을 사용했을 때는 다른 prompt enginnering 기법보다 15~45% 성능이 좋았다.
- learning 기반 접근 방식임에도 불구하고, 직접 만든 prompts를 사용한 zero-shot model에 비해 더 뛰어난 도메인 일반화 성능을 보인다.
🦾 Introduction
기존의 연구
discrete label을 이용하여 fixed set of object categories를 예측했었다. 즉, 카테고리의 text들은 인덱싱을 거쳐, discrete label로 된 것이다.
예를 들어 gold fish와 toilet paper와 같은 단어들은 단지, cross-entropy loss를 용이하게 하기 위한 discrete label로 분류될 뿐, text에 내포된 의미를 직접적으로 사용한 것이 아니다.
즉, 기존에 사용되는 label들은 text의 의미를 이미지 특성과 매칭시킬 수 없다는 것이다.
이러한 학습 방법은 visual recognition system을 폐쇠된 시각적 개념에 한정시키고, 새로운 categories에 대해 다룰 수 없도록 한다.
Vision-Language Learning
그래서 CLIP과 같은 vision-language 모델이 시각 표현 학습의 대안으로 사용되었다.
주요 아이디어는 Image Encoder와 Text Encode 총 두 개의 인코더에서 image와 raw text를 정렬하는 것이다. 이 모델들은 image-text pair에 대해 positive이면 feature space 상에서 가까워지도록 하고, negative pair이면 멀어지도록 학습한다.
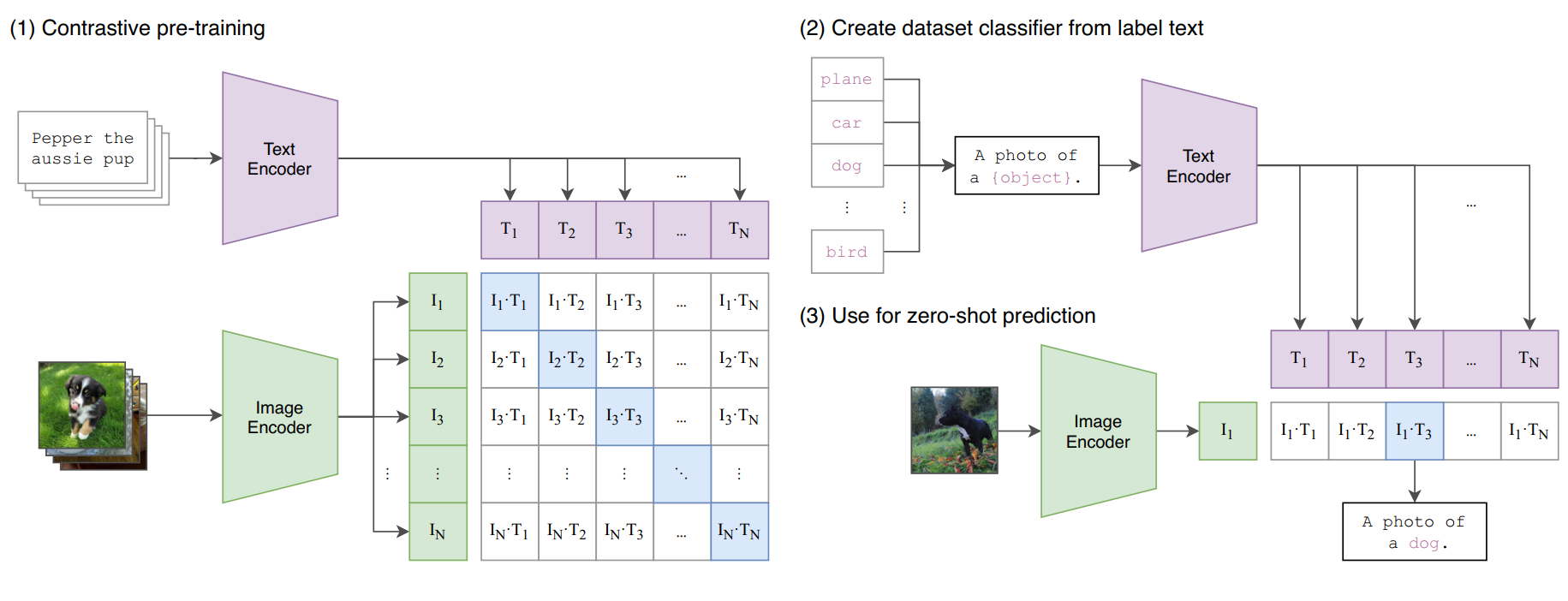
기존 VL model에서의 한계점
그러나 Abstract에서 언급했듯이, 한계점이 존재한다.
- word tuning을 하는 데에는 상당한 시간이 소모된다.
- 단어 구조의 작은 변경으로도 성능에 큰 영향을 끼친다. 아래 사진과 같이
photo라는 단어 추가에 약 5% 성능이 향상되고,[CLASS]의 위치에도 큰 영향을 받는 것을 볼 수 있다.
- task에 대한 사전 지식과, 언어 모델에 대한 지식이 필요하다.
CoOp
NLP에서 영감을 받아 prompt engineering을 자동화 하는 접근 방식으로 CoOp을 제안하였다.
※ CoOp의 Method에 대해서는 너무 여러 번 언급되는 감이 있어 Method 부분에서 다루도록 하겠습니다!
🦾 Contributions
text prompt를 discrete category로 생각 (기존의 prompt engineering) 하지 않고, continuous signal로 취급하였다.
- 기존의 VLP 방식에서의 비효율적인 문제점들을 제시하였다.
- pre-trained VL model을 통해 prompt engineering이 자동화될 수 있도록, continuous prompt learning 방식으로 접근하였다.
- 구현 방식을 unified / class specific 두 가지로 제시함으로써 다양한 recognition task에 적용될 수 있는 방법을 제시하였다.
- hand crafted prompt 방식과, linear probe model 방식에 비해 더 효율적으로 최적화가 가능하며, 성능이 현저히 높아졌으며, domain shift에 보다 더 robust 하다.
🦾 Related Works
※ 논문의 내용을 자세히 나열하기 보다, 필요한 부분만 작성하였습니다.
Vision Language Model
이 논문에서의 목표는 VL model에 대한 연구라기 보다, 이 모델들을 downstream task에 적응시키고 전이하는 것을 효율화 시키는 것에 중점을 두고 있다.
Prompt Learning in NLP
- probing : 주어진 cloze-style에 대해 정답을 생성하게 하는 것
- knowledge probing :
fill-in-the-blank(빈칸 채우기) 방식의 cloze texts 방법이 제시되었다.
본 논문에서 채택한 prompt learning 방식은 continuous prompt learning이다. 이는, word embedding space에서 continuous한 벡터를 사용하는 방식이다.
하지만 이 방식은 문제점이 있다. 학습된 word가 정확히 어떤 prompt를 나타내는지 시각화를 할 수 없다.
그래도 이 방식을 채택한 이유는 prompt embedding을 추출하는 것이 목적이 아닌, VL model을 downstream task에 적용하여 성능이 좋고, domain shift에 강인한 prompt를 자동화하기 위함이다.
🦾 Method
[1] Vision-Language Pre-training
➡️ Models
두 개의 인코더를 가지고 있고, 하나는 image, 하나는 text encoder이다. CLIP baseline이다.
-
Image Encoder
- high-dimensional image를 low-dimensional embedding space로 mapping한다.
- ResNet50의 CNN과 ViT의 transformer baseline처럼 사용하였다.
-
Text Encoder
: transformer
➡️ Encoding 방식
각 text sequence는 [SOS], [EOS] 토큰으로 둘러싸이고, 고정된 길이로 제한된다.
고정된 길이[77]보다 짧은 시퀀스는 padding 토큰으로 채워지고, 초과하면 시퀀스가 잘려나간다.
➡️ Training
image-text pair에 대해 CLIP은 matched pair면 cosine similarity를 최대화시키고, unmatched pair면 최소화 시킨다.
➡️ Zero-shot Inference
CLIP은 웹 기반으로 다양하고 많은 text prompt로부터 학습이 되어 있다. 그렇기에 zero-shot inference 성능이 높다.
f : image encoder를 통과하여 얻은 feature
K : downstream task의 클래스 개수
cos : cosine similarity
w_i : text encoder를 통과하여 얻은 weight
[2] Context Optimization (CoOp)
pre-trained model의 parameter를 고정한 상태로, 데이터로부터 continuous vector로 context word를 모델링하여 manual prompt tuning(수동 프롬프트 조정)을 피하는 방법이다.
구현 방법은 두 가지이다.
➡️ Unified Context
모든 클래스에 same context를 공유하는 방법이다.
[CLASS]토큰을 수식 끝 [end]에 넣을 수도 있고, ex)a photo of a [CLASS]- 수식 중간 [mid]에 넣을 수도 있다. ex)
a photo of a [CLASS], a type of object
➡️ Class-Specific Context (CSC)
각 클래스에 대해 독립적인 context vectors를 사용한다. CSC는 fine-grained classification task에 유리하다.
🦾 Experiments
사용한 데이터셋은 총 11개이다. ➡️ ImageNet, Caltech101, Oxford-Pets, StanfordCars, Flowers102, Food101, FGVCAircraft, SUN397, DTD, EuroSAT, UCF101
실험은 class token의 position과 구현 방식, context length에 따라 각각 진행된다.
backbone에 대한 실험을 제외하고는 모두 ResNet-50을 사용하였다. CoOp’s context vectors는 무작위로 초기화하였으며, 그 외의 train 설정은 논문을 참고하길 바란다.
📈 Hand-Crafted prompts와 비교
CoOp’s context length를 16으로 지정했을 때, Food101 Dataset을 제외하고는 모두 zero-shot CLIP보다 성능이 1.24~45.97% 향상된 것을 확인할 수 있다.
📈 Linear Prob CLIP과의 비교
Linear Probing이 CLIP+CoOp(end/mid, CSC) 보다 높은 성능을 보인 Dataset들이 있었지만, 평균적으로 보았을 때 Linear Probing보다 CoOp 방식을 사용하였을 때, 성능이 더 우수한 것을 볼 수 있다.
위 table은 Domain Shift에 대한 성능 확인으로 Linear Probing보다 대략 7~10% 정도 높은 robustness를 보인다.
📈 Unified vs Class-Specific Context
논문의 fig3을 참고한 결과, 대게 Unified Context 방식이 더 좋은 성능을 내었다. 그러나 더 높은 sample 수에서 Flower102, FGVAircraft, DTD, EuroSAT에서의 결과는 CSC가 더 높은 성능을 보이는 것을 확인할 수 있었다.
📈 Context Length
Domain Shift에서의 성능을 언급했던 Figure에서는 M=4(shorter context length)에서의 성능이 M=16일 때의 성능보다 높은 것을 볼 수 있었다. ➡️ 이는 적은 파라미터를 사용하여 더 적은 오버피팅을 보였기 때문이다.
그러나 일반 Source에 대한 성능을 확인해본 결과 context token이 더 많을 수록 성능이 좋은 것을 확인할 수 있었다.
논문에서는 ‘context 길이가 길수록 token을 중간(mid)에 위치시키는 것이 더 좋다’라고 주장을 하지만, 그래프에서 확인했을 때는 말과 일치하지가 않아 이 부분은 혼동이 옵니다. 아시는 분들은 피드백 부탁합니다!
결론적으로는, domain shift와 성능 사이에서의 context length 황금 비율은 없다는 것이다.
📈 그 외의 부수적인 Results
- Vision Backbone : backbone 구조가 성장할 수록 더 좋은 성능을 내었으며, backbone 구조와 무관하게 CoOp 방식이 성능 향상을 잘 이끌었다는 것을 보였다.
- Prompt Ensembling과의 비교 : prompt engineering < prompt ensembling < CoOp으로 성능이 좋았으며, prompt ensembling보다 2.54~4.07% 높은 성능을 보였다.
- 다른 Fine Tuning과의 비교 : text encoder를 통과하는 gradient가 더 유용한 정보를 제공하는 것을 확인할 수 있었고, CoOp의 성능이 가장 우수함을 확인할 수 있었다.
🦾 Conclusions
- 대규모 Vision model을 prompt learning으로 적응시키는 첫 번째 종합적인 연구이다.
- Domain 일반화와 기본적인 성능이 수동 prompt보다 훨씬 높은 성능을 도출한다.
- Continuous 방식을 채택하였기 때문에, 해석하기가 상대적으로 어렵다.
- Food101 dataset에서 약한 성능을 보인 것을 보아, noise가 많은 label에 민감하다.
🦾 CoOp 논문에 대한 나의 생각
prompt 자체를 자동화한 것이 매우 혁신적인 아이디어라고 생각되었다. 이를 통해 domain 일반화에서 기존 연구된 기법들보다 훨씬 높은 성능을 얻은 것이 가장 인상 깊었던 것 같다. 아쉬운 점이 있다면, 논문의 명확성이 부족했던 것 같다. 그러나 Abstract부터 Introduction, Method 곳곳에 핵심적이라고 생각되는 부분들을 여러 번 언급하여 저자가 말하고자 하는 핵심 내용들과 CoOp의 기여를 알 수 있었다.

Leave a comment